Date: Sat, 2 Apr 2016 16:23:26 +0530
We tested the Intel branch for scaling with the recently launched Broadwell-EP servers for two GB workloads Nucleosome(~25K atoms) and Rubisco (~75K atoms).
For large GB workloads MPI + OpenMP scales better than just MPI alone.
Details are as follows:
Server Configuration:
Model: Intel(R) Xeon(R) CPU E5-2697 v4 . 2.30GHz (Broadwell-EP)
Thread(s) per core: 2
Core(s) per socket: 18
Socket(s): 2
NUMA node(s): 2
Software versions for Intel build
[Xnrai.ewb266 ~]$ which ifort
/opt/intel/compiler/2016u1/compilers_and_libraries_2016.1.150/linux/bin/intel64/ifort
[Xnrai.ewb266 ~]$ which mpiifort
/opt/intel/impi/5.1.2.150/compilers_and_libraries_2016.1.150/linux/mpi/intel64/bin/mpiifort
[Xnrai.ewb266 ~]$ ifort -v
ifort version 16.0.1
[Xnrai.ewb266 ~]$ mpiifort -v
mpiifort for the Intel(R) MPI Library 5.1.2 for Linux*
Copyright(C) 2003-2015, Intel Corporation. All rights reserved.
ifort version 16.0.1
Software versions for GNU build
[Xnrai.ewb266 ~]$ which mpif90
~/panfs/opt/mpich-3.2/bin/mpif90
[Xnrai.ewb266 ~]$ which gfortran
~/panfs/opt/gcc/gcc-5.3.0/bin/gfortran
[Xnrai.ewb266 ~]$ gfortran -v
Using built-in specs.
COLLECT_GCC=gfortran
COLLECT_LTO_WRAPPER=/panfs/panfs3/users1/Xnrai/opt/gcc/gcc-5.3.0/bin/../libexec/gcc/x86_64-unknown-linux-gnu/5.3.0/lto-wrapper
Target: x86_64-unknown-linux-gnu
Configured with: ./configure --disable-checking --enable-languages=c,c++,fortran --disable-multilib --with-system-zlib -- prefix=/home/Xnrai/panfs/opt/gcc/gcc-5.3.0/ --with-gmp=/home/Xnrai/panfs/opt/gmp-6.1.0 --with-mpfr=/home/Xnrai/panfs/opt/mpfr-3.1.3 --with- mpc=/home/Xnrai/panfs/opt/mpc-1.0.3/
Thread model: posix
gcc version 5.3.0 (GCC)
[Xnrai.ewb266 ~]$ mpif90 -v
mpifort for MPICH version 3.2
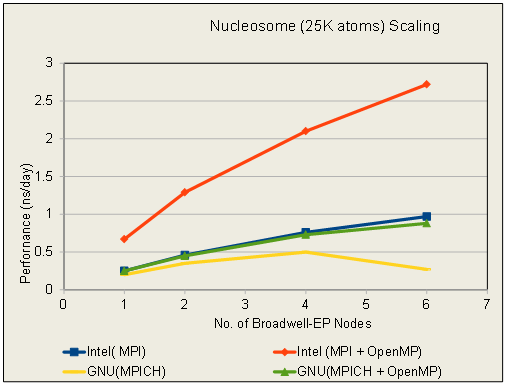
Nucleosome Performance in ns/day
Number of Servers
Intel
GNU
MPI
MPI + OpenMP
MPICH
MPICH + OpenMP
1
0.25
0.67
0.2
0.25
2
0.46
1.29
0.35
0.45
4
0.76
2.1
0.5
0.73
6
0.97
2.72
0.27
0.88
(See attached file: Nucleosome_Scaling.PNG)
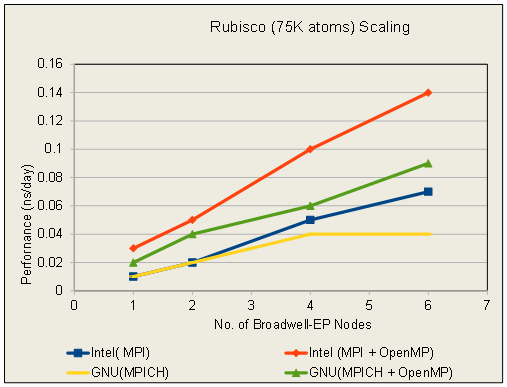
Rubisco Performance in ns/day
Number of Servers
Intel
GNU
MPI
MPI + OpenMP
MPICH
MPICH + OpenMP
1
0.01
0.03
0.01
0.02
2
0.02
0.05
0.02
0.04
4
0.05
0.1
0.04
0.06
6
0.07
0.14
0.04
0.09
(See attached file: Rubisco_Scaling.PNG)
Regards,
Nitin Rai
-----Jason Swails <jason.swails.gmail.com> wrote: -----
To: AMBER Developers Mailing List <amber-developers.ambermd.org>
From: Jason Swails <jason.swails.gmail.com>
Date: 03/24/2016 07:08AM
Subject: Re: [AMBER-Developers] reference os+compiler systems
I found some compiler performance comparisons I did awhile ago (March,
2014)! All are in serial with the same short calculation using exactly the
same input files. Far from comprehensive, but it gives a decent overview
of relative performance
g++ w/ dragonegg, gfortran w/ dragonegg
cpptraj: 57.6 s
pmemd: 119.5 s
QM/MM sander: 252.1 s
clang++, gfortran w/dragonegg
cpptraj: 60.8 s
pmemd: 119.6 s
QM/MM sander: 252.7 s
g++, gfortran (4.7)
cpptraj: 72.1 s
pmemd: 110.8 s
QM/MM sander: 250.5 s
icpc, ifort (13.1.2)
cpptraj: 55.4 s
pmemd: 94.0 s
QM/MM sander: 208.6 s
The Intel compilers *also* had the MKL, so that might be a lot of why QM/MM
was so much faster. But we get Intel speedups practically across the board
for the Intel compilers. I'm not sure what later versions of GCC look
like, but I did test across many versions (4.1 through 4.6 or 4.7, IIRC),
and the performance was basically unchanged.
All the best,
Jason
On Thu, Mar 10, 2016 at 9:26 PM, Jason Swails <jason.swails.gmail.com>
wrote:
> Oh, and cygwin is a special beast. For Gerald -- nobody is going to run
> SEBOMD on Cygwin. So if it doesn't work there, I vote for just throwing in
> some preprocessor-protected bomb code that simply exits with a helpful
> error and refuses to run on that platform.
>
> It's nice to support Cygwin (and will eventually help us to natively
> support Windows -- which is actually pretty close to being a reality), but
> in some cases the reward just does not justify the required effort.
>
> All the best,
> Jason
>
> On Thu, Mar 10, 2016 at 9:23 PM, Jason Swails <jason.swails.gmail.com>
> wrote:
>
>> It's been a long time since I've done benchmarks between GNU, Intel, and
>> LLVM compilers (at the time, GCC didn't go past 4.8, I think). But here's
>> what I remember:
>>
>> DragonEgg + gfortran was indistinguishable from gfortran in terms of
>> performance (DragonEgg+gfortran compiles in ~1/2 the time, though, which is
>> why I've exclusively used DragonEgg when compiling Amber for the past
>> several years).
>>
>> Performance for GCC 4.1, 4.2, 4.3, 4.4, 4.5, 4.6, 4.7, and 4.8 was
>> basically unchanged for both pmemd and cpptraj using the standard
>> config.h-provided compiler flags (I have all GCCs from 4.1 through 4.9 and
>> 5.2 on my Gentoo box). It could be that the gfortran developers focused
>> heavily on Fortran performance for the 5.x series, but I actually suspect
>> that's not too much the case.
>>
>> The Intel Fortran compiler was notably faster, especially with MKL for
>> certain things that used it. The improvements were more pronounced than
>> Dan's report below on my machine (AMD FX-6100 hex-core).
>>
>> For C++ performance, g++ was the slowest (by a considerable margin),
>> clang++ was faster, and icpc was a little faster still (but not a lot).
>> But that's application-dependent. ÿFor OpenMM, Robert McGibbon did some
>> benchmarks comparing clang++, g++, and icpc and actually showed that
>> clang++ was, by a considerable margin, the best compiler (for heavily
>> optimized code vectorized with compiler intrinsics) -- here is the report:
>> http://bit.ly/1Maw6Ps
>>
>> But performance is not the only reason to like a compiler. ÿGCC 4.9 and
>> up, and clang (for quite a bit longer) gives significantly improved
>> compile-time analysis on the code (and clang gives quite good run-time
>> error-checking as well: http://bit.ly/1RaY2nB
>>
>> In any case, I have very frequently taken advantage of multiple compilers
>> to find bugs and fix them. ÿFor instance, what might be a heisenbug in
>> gcc/gfortran may segfault in icc/ifort and vice-versa. ÿAnyone that's done
>> a lot of debugging knows that segfaults are *way* easier to debug. ÿThere
>> have also been instances where a Heisenbug with one compiler doesn't even
>> show up in another -- same thing with different MPI libraries; I've fixed
>> bugs that OpenMPI exposed that mpich2 effectively masked.
>>
>> So I think we should have 3 categories of compilers:
>>
>> 1. Those we test regularly (certain versions of GCC, Intel, and
>> clang/LLVM) and know to work well on any systems we use
>> 2. Those that don't support the language features we rely on and so are
>> expressly unsupported (GCC 4.1.2 and earlier), and compiler families we
>> never test
>> 3. Everything else. ÿIt *should* work, but is not thoroughly tested
>> (which is why we have regression tests that users can run).
>>
>> It would be good to document which are in category 1 somewhere, but I
>> think striving to support as many compilers as possible is, on the whole,
>> good for Amber.
>>
>> All the best,
>> Jason
>>
>> On Thu, Mar 10, 2016 at 3:05 PM, Daniel Roe <daniel.r.roe.gmail.com>
>> wrote:
>>
>>> Benchmarks for my local machine (intel core i7-2600 3.4 GHz), x86_64.
>>> Current GIT master (8685600c1b3862670b1de0549776a687c1520aea).
>>> $AMBERHOME/benchmarks/dhfr
>>>
>>> GNU: 5.3.1
>>> ./configure gnu
>>> sander: 0.49 ns/day
>>> pmemd: 1.13 ns/day
>>>
>>> Intel: 14.0.0
>>> ./configure intel
>>> sander: 0.55 ns/day
>>> pmemd: 1.42 ns/day
>>>
>>> About 1.1-1.2x - not as large as the speedup that Ross saw but still not
>>> bad.
>>>
>>> I'll look at some cpptraj benchmarks in a bit.
>>>
>>> -Dan
>>>
>>> On Thu, Mar 10, 2016 at 12:53 PM, Gerald Monard
>>> <Gerald.Monard.univ-lorraine.fr> wrote:
>>> >
>>> >
>>> > On 03/10/2016 06:03 PM, David A Case wrote:
>>> >> Could you say how much faster (for some example)? ÿ(Aside: you can
>>> use MKL
>>> >> + gnu compilers, if that makes any difference).
>>> >>
>>> >> ...thx...dac
>>> >
>>> > I'll try to provide some benchmarks for next week.
>>> > Best,
>>> >
>>> > Gerald.
>>> >
>>> >
>>> > --
>>> >
>>> ____________________________________________________________________________
>>> >
>>> > ÿ Prof. Gerald MONARD
>>> > ÿ SRSMC, Universit‚ de Lorraine, CNRS
>>> > ÿ Boulevard des Aiguillettes B.P. 70239
>>> > ÿ F-54506 Vandoeuvre-les-Nancy, FRANCE
>>> >
>>> > ÿ e-mail : Gerald.Monard.univ-lorraine.fr
>>> > ÿ tel. ÿ : +33 (0)383.684.381
>>> > ÿ fax ÿ ÿ: +33 (0)383.684.371
>>> > ÿ web ÿ ÿ: http://www.monard.info
>>> >
>>> >
>>> ____________________________________________________________________________
>>> >
>>> >
>>> > _______________________________________________
>>> > AMBER-Developers mailing list
>>> > AMBER-Developers.ambermd.org
>>> > http://lists.ambermd.org/mailman/listinfo/amber-developers
>>>
>>>
>>>
>>> --
>>> -------------------------
>>> Daniel R. Roe, PhD
>>> Department of Medicinal Chemistry
>>> University of Utah
>>> 30 South 2000 East, Room 307
>>> Salt Lake City, UT 84112-5820
>>> http://home.chpc.utah.edu/~cheatham/
>>> (801) 587-9652
>>> (801) 585-6208 (Fax)
>>>
>>> _______________________________________________
>>> AMBER-Developers mailing list
>>> AMBER-Developers.ambermd.org
>>> http://lists.ambermd.org/mailman/listinfo/amber-developers
>>>
>>
>>
>>
>> --
>> Jason M. Swails
>> BioMaPS,
>> Rutgers University
>> Postdoctoral Researcher
>>
>
>
>
> --
> Jason M. Swails
> BioMaPS,
> Rutgers University
> Postdoctoral Researcher
>
-- Jason M. Swails _______________________________________________ AMBER-Developers mailing list AMBER-Developers.ambermd.org http://lists.ambermd.org/mailman/listinfo/amber-developers =====-----=====-----===== Notice: The information contained in this e-mail message and/or attachments to it may contain confidential or privileged information. If you are not the intended recipient, any dissemination, use, review, distribution, printing or copying of the information contained in this e-mail message and/or attachments to it are strictly prohibited. If you have received this communication in error, please notify us by reply e-mail or telephone and immediately and permanently delete the message and any attachments. Thank you
_______________________________________________
AMBER-Developers mailing list
AMBER-Developers.ambermd.org
http://lists.ambermd.org/mailman/listinfo/amber-developers
(image/png attachment: Rubisco_Scaling.PNG)
(image/png attachment: Nucleosome_Scaling.PNG)
